Казаков Олег,
эксперт-аналитик
Филиала некоммерческой организации
«Эволюшн энд Филантропи» в РФ
Impact Genome Project – это коммерческий проект американской фирмы Mission Measurement (http://missionmeasurement.com), специализирующейся на разработке измерителей социальных изменений. Руководитель фирмы Джейсон Сол (Jason Saul) взялся решить амбициозную задачу – найти такой универсальный набор показателей проекта, зная которые, можно достаточно точно предсказать результат (outcome) его выполнения. Подобно тому как в геноме человека закодированы все свойства конкретного организма, Сол предположил, что существует и «программный геном», а в составе «генов» конкретного проекта «закодированы» все его результаты.

Проект разработки программного генома продвинулся, когда к нему подключился музыковед Нолан Гассер (Nolan Gasser). В 2000 году Гассер по заказу одной из американских музыкальных радиостанций не без успеха применил модель генома к музыкальным произведениям, предположив, что существует ограниченный набор параметров музыкального произведения, зная который, можно предсказать, какой эффект оно произведёт на конкретного человека, т.е. понравится ли оно ему. Набор «генов» двух разных музыкальных произведений позволяет определить и «расстояние» между ними, характеризующее степень близости в смысле «нравится-не нравится». Имея такую конструкцию можно предсказывать, понравится ли вам конкретное произведение, если известно, что вам нравится некоторое другое. Здесь важно отметить, что сконструированный «геном музыки» предназначен для предсказания конкретной характеристики – «нравится-не нравится». И он не применим для того, чтобы прогнозировать другие свойства музыкального произведения. Например, станет ли оно хитом, т.е. каков будет его коммерческий успех, или будет ли оно признано относящимся к новому музыкальному стилю, какое влияние оно окажет на развитие теории музыки и музыкальной культуры.

Аналогичный подход Сол и Гассер применили к результатам социальных проектов для решения задачи прогнозирования их результативности/успешности. В принципе, качественные методы прогноза (по мнению экспертов) применялись всегда. Экспертный подход уже давно применяется в рутинном порядке.
Разработка «программного генома» позволяет использовать количественные методы, одновременно способствуя применению рыночной терминологии и рыночных механизмов к социальным проектам и их эффектам. Так, речь может идти о «рынке социальных программ», на котором осуществляется «торговля социальными результатами». Занимаясь фандрайзингом сейчас, вы предлагаете донору умозрительный образ будущего. Планируемый результат при этом трудно соотнести с запрашиваемыми на его реализацию ресурсами. Теперь же у вас есть возможность предложить «купить» конкретный социальный результат (outcome) по конкретной цене. Например, не «повышение уровня жизни», а конкретное «количество семей, поднявшихся из группы бедных в средний класс». И покупатель имеет возможность посмотреть, по какой цене «продают» этот же результат другие «поставщики» (исполнители социальных проектов) или какие другие социальные результаты он может «купить» за ту же цену.
В этом смысле авторы нового подхода считают, что мы стоим перед серьёзными изменениями, чуть ли не на пороге революции в сфере производства социальных благ. Место фандрайзера займёт социальный брокер, фонды будут представлять собой «брокерские конторы», а для НКО будут применимы «котировки» на своеобразной «фондовой бирже».
Авторы не скрывают, что метод «социального генома» не даёт оценок и прогноза с высокой точностью, но они дают инструмент, позволяющий повысить точность по сравнению с имеющимися в настоящее время методами.
Создание программного генома
В основе разработанной Mission Measurement методики лежат две идеи – универсализация и сравнительный анализ (benchmarking).
Воспользовались большим массивом уже выполненных проектов, авторы методики построили универсальную модель социального проекта, сведя любой такой проект к набору количественных программных показателей-факторов (factors). Подробности того, как производился отбор этих показателей, не сообщается. Параллельно они описали имеющийся массив проект в терминах построенной модели (эта работа ещё не завершена). Это дало формальное описание накопленного практического опыта в форме легко используемой базы данных (её можно даже назвать базой знаний). Одновременно для этих же проектов была произведена количественная оценка их результатов (outcomes). Предварительно был составлен универсальный каталог всех возможных результатов. Универсальное формальное описание, применимое к любому новому проекту, позволяет сравнить его с проектами, содержащимися в этой базе, и на этой основе предсказать его результативность. Зная программные параметры-факторы, можно отобрать из базы данных проектов схожие с ним и, усреднив их результаты, выдать их за прогноз планируемого проекта. Авторы апеллируют к опыту бизнес-сообщества, где все прогнозы делаются на основании мощнейшего анализа прошлого опыта и где постоянно ведётся сбор данных. Это также смыкается с концепцией больших данных (big data). До сих пор каждый завершённый проект оставляет гору слабо структурированной документации. Даже если эти сведения доступны, они крайне неудобны для обработки, поскольку информация представлена нестандартизованно. Тем самым, для построения прогноза применяется «сравнение с известными примерами» (benchmarking). База данных уже завершённых проектов с известными результатами выступает ориентиром для оценки результативности нового проекта.
И для моделирования, и для последующих оценок авторы воспользовались документами о 78369 проектов. Эта база была сформирована из архивов различных публичных и частных организаций. Однако об её представительности судить сложно, границы применимости непонятны. Действуя формально, любой проект можно сопоставить с этой накопленной информацией, но можно ли считать приемлемыми прогнозы успешности обучения иностранному языку на основе данных об успешности аналогичных проектов обучения математике? Или сравнивать идентичные проекты, реализуемые в США и России?
Во-первых, этот массив проектов был использован для того, чтобы построить универсальный каталог социальных результатов или целей (universal outcomes taxonomy). Несмотря на то, что были использованы наработки нескольких исследовательских центров, эта работа заняла 2 года. В итоге был создан всеобъемлющий каталог (или классификатор), содержащий 132 позиции.
Каталог представляет собой четырёхуровневый классификатор: сфера деятельности (например, образование); подотрасль или тип проекта (среднее образование); цель (повышение доступа к образованию) и подцель (повышение квалификации учителей). Например, к сфере образования относится 25 возможных социальных результатов (целей). Фрагмент каталога представлен на нижеследующем рисунке. Полная версия каталога нигде не опубликована, но это вопрос времени. Видимо, его отладка продолжается.
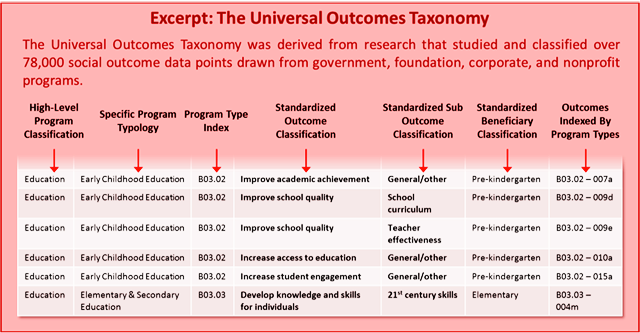
Утверждается, что этот каталог всеобъемлющ, т.е. цель любого проекта можно найти в этом каталоге, как бы мы её не формулировали. Такой классификатор даёт «единый язык» формулировки целей своей деятельности, что может оказаться полезным для доноров.
Во-вторых, сформирован перечень социальных групп (целевые или адресные группы проекта). Например, «дети дошкольного возраста». Количество таких групп неизвестно.
Формирование такого перечня вылилось в отдельную работу. Понятно, что группа стейкхолдеров (благополучателей, бенефициариев) – важнейшая характеристика любого проекта, но не очень понятно, почему эти группы «привязаны» к каталогу целей. Это можно видеть и на приведённом рисунке. Видимо, формулировка некоторых целей неотделима от указания на бенефициариев. И, наоборот, совершенно разные цели могут относиться к разным целевым группам.
В-третьих, на основе имеющейся базы данных проектов для каждой позиции в каталоге социальных результатов (outcomes) был сформирован свой набор программных параметров – определённый ограниченный набор числовых величин. Этот набор и называется программным геномом. Фактически, геном – это способ кодификации любого проекта (по большому счёту – любой деятельности). Вполне возможно, наборы программных параметров (генов) для проектов с разными социальными результатами пересекаются, но важно, что отнесение проекта к определённому социальному результату однозначно определяет набор ключевых программных параметров.
Авторы разработки называют программные параметры факторами. Их действительно можно рассматривать как наборы факторов, определяющих результативность проекта применительно к конкретной цели проекта. Для проектов, имеющих разные цели (или планируемые социальные результаты), эти наборы факторов различны. Геном для конкретного социального результата (цели) и подбирался, исходя из того, что он должен достаточно точно объяснять его результативность. Именно результативность проекта (способность успешного достижения своей цели), а не что-то иное.
Как формировались эти наборы для каждой из 132 позиций каталога социальных результатов, не раскрывается. Собственно эта работа проделана пока не для всех 132 программных результатов (целей). Видимо, она завершена только для сферы образования (25 социальных результатов). В общей сложности для образовательных проектов выделено более 400 программных параметров-факторов. Число таких ключевых факторов, соответствующих определённому социальному результату, варьируется. Обычно их 2-3 десятка, если судить по приводимым примерам. Полный список не опубликован, но это, видимо, из-за его неготовности.
Что представляют собой эти параметры-факторы, можно судить только по отдельным примерам. Ясно, что каждый из них – это количественная величина. Их значения для конкретного проекта устанавливается экспертным образом и не стандартизовано до такой степени, чтобы это можно было легко и однозначно сделать самостоятельно разработчикам проектов. Сейчас такая услуга предоставляется самой фирмой и кодировку проекта осуществляют сотрудники Mission Measurement. Какая квалификация для этого необходима – непонятно.
Параметры-факторы подобраны таким образом, чтобы по их значениям близость проектов означала и близость результативности. Оценив эти значения для разрабатываемого проекта, можно потом по базе данных уже выполненных проектов, используя уже известную для них результативность, спрогнозировать и результативность ещё только разрабатываемого проекта. Или проекта, дизайн которого представлен донору, грантодателю, спонсору.
Подробности о «мере близости» проектов по значениям их параметров-факторов и о том, как из базы проектов отбираются те, по которым вычисляется прогноз, не приводятся. Собственно это составляет главное «ноу-хау» авторов методики. Для решения таких задач можно применить многие уже хорошо разработанные математические методы. Но в любом случае остаётся главный вопрос: насколько универсальна предложенная модель? И не важно, какие методы применялись для её разработки.
Тем самым, на основе опыта выполнения более 80 тысяч проектов в Mission Measurement:
(1) разработан универсальный каталог социальных результатов;
(2) сформирован полных перечень возможных бенефициарных групп;
(3) для каждого социального результата разработан набор программных параметров-факторов, используемых для кодировки проектов, нацеленных на достижение этого социального результата;
(4) подобрана (сконструирована) мера близости (схожести) двух разных проектов, исходя из набора параметров-факторов;
(5) разработаны алгоритмы отбора из базы данных проектов таких, по которым строится прогноз результативности нового проекта, и вычисления прогнозных значений (действенность);
(6) сформирована база данных о тысячах проектов;
(7) осуществлена их кодировка.
Многие из этих задач не решены полностью или окончательно. Видимо, именно в решение этих задач фирмой вложен 1 миллион долларов.
Продукт
Основной предсказываемый показатель – действенность (отдача) проекта (Efficacy Rate), который показывает, в каком проценте случаев проект достигнет запланированного результата (outcome). Например, реализуется проект ликвидации безграмотности. Если из 1000 человек, которые участвовали в проекте, 900 стали грамотными, то действенность проекта составляет 90%. Этот показатель предсказывается на основе сведений о том, каков успех был у схожих проектов, данные о которых имеются в базе данных.
Два других показателя вычисляют исходя из первого и двух запланированных параметров оцениваемого проекта – сколько всего бенефициариев/клиентов предполагается охватить проектом и предполагаемая стоимость проекта.
Ожидаемый результат (Expected outcomes) – абсолютное число успешных случаев. Если предполагается охватить проектом 100 семей, а предсказанный показатель действенности 12%, то цели проекта будут достигнуты для 12 семей.
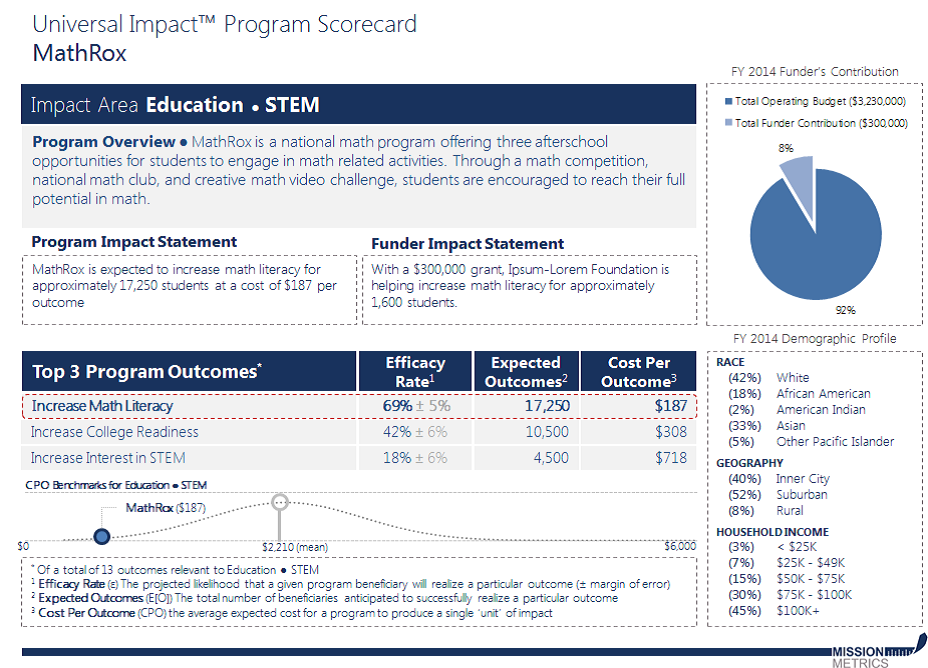
Третий вычисляемый показатель – стоимость достижения запланированного результата на одного бенефициария (Cost Per Outcome). Можно сказать «себестоимость успеха». Например, если в проекте предусмотрено оказать помощь 100 заёмщикам, попавшим в «кредитное рабство». Действенность проекта прогнозируется в 20%, т.е. предсказывается, что 20 человек решать свои проблемы с кредиторами. Если на всю программу предполагается потратить 200 рублей, то стоимость решения проблемы для одного клиента составляет 10 рублей (=200/20).
Эти три показателя вычисляются для всех запланированных/желаемых результатов или целей (outcomes) проекта. Их может быть несколько.
Собственно стандартная «универсальная карта количественного прогноза проекта» (Universal Impact Program Scorecard) содержит эти три прогнозных значения. Напомним ещё раз: прогнозируется только одно значение, первое, остальные вычисляются, исходя из запланированных масштабов анализируемого проекта.
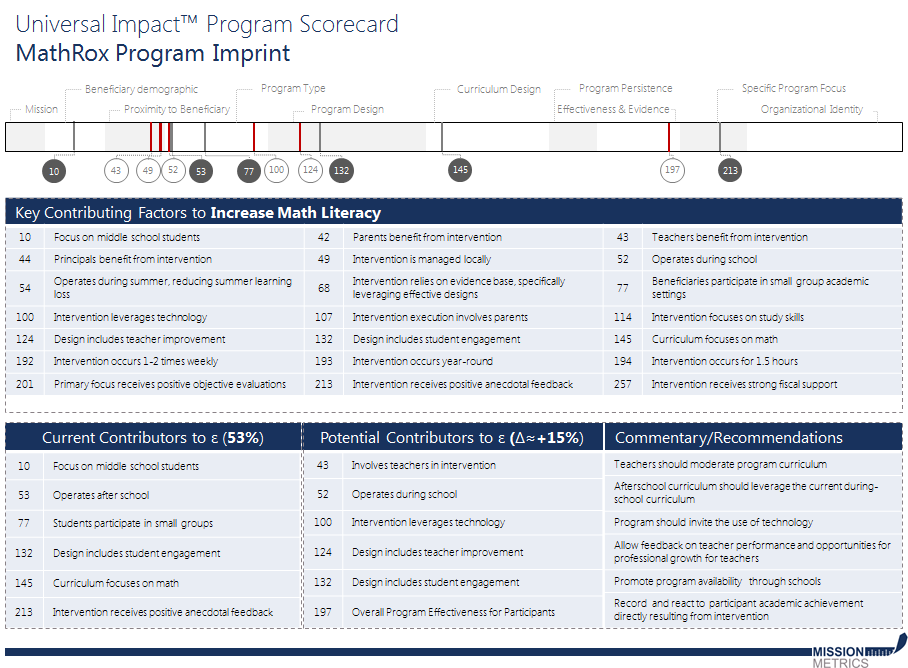
В дополнение к этому стандартный вариант Карты содержит перечень всех «генов» – параметров-факторов проекта (Key Contributing Factors), которые применимы (оказывают влияние) к запланированному результату (outcome – Increase Math Literacy). Для другого результата этот набор будет иным. Однако, анализируемый проект использует не все факторы. Они тоже перечислены в карте (Current Contributors). Именно они и обеспечивают прогнозируемое значение действенности проекта (53%). Не используемые (не действующие) факторы (Current Contributors) – потенциал для повышения отдачи (действенности) проекта (в представленном примере этот потенциал составляет 15%). Эти факторы тоже перечислены (Current Contributors) и по каждому из них даётся рекомендация (Commentary/Recommendation).
В приведённом примере ключевых параметров-факторов для запланированного социального результата указано 21. Непонятно, полный ли это набор. На рисунке в верхней части Карты в кружочках отмечено 12 факторов. 6 светлых кружков с числами обозначают факторы, действующие для оцениваемого проекта. 6 тёмных кружков – те, которые ещё можно задействовать. В светлых кружках на рисунке есть несоответствие приведённому ниже перечню – где ошибка, хотя странно, как компьютерная программа может содержать такую ошибку. Возможно, мы неверно трактуем этот рисунок.
Рисунок также даёт графическое представление «программного генома». Видно, что все «гены», количество которых непонятно, объединены в следующие 10 групп:
1) Миссия (Mission)
2) Благополучатели, включая географическую привязку (Beneficiary geographic)
3) Близость (вовлечение) к благополучателям (Proximity to Beneficiary)
4) Тип проекта (Program Type)
5) Program Design (дизайн проекта)
6) Дизайн образовательного курса (Curriculum Design)
7) Постоянство проекта (Program Persistence)
8) Эффективность и свидетельства (Effectiveness & Evidence)
9) Особенности проекта (Specific Program Focus)
10) Спецификация организации-исполнителя (Organizational Identity)
Указанные в примере программные параметры-факторы по всей видимости относятся к проектам в сфере образования. Видимо, также, что их нумерация (последовательность) не несёт содержательного смысла. Приведённый выше перевод наименований группировок параметров можно сделать более точным, если располагать полным перечнем параметров в каждой группе.
Поскольку прогнозное значение вычисляется по нескольким проектам (из базы данных), которые схожи с анализируемым проектом, то это позволяет выдать о них ещё много различных сведений – в частности, в упомянутом выше примере Карты приводится распределение «цены социального результата» (Cost Per Outcome) – смотри раздел Карты под заголовком CPO Benchmarks for Education/STEM (распределение цены социального результата для образовательных проектов по теме «Наука, Технологии, Инженерное дело, Математика»). Например, можно посмотреть, сколько стоили эти проекты, сколько они продолжались по времени. Можно даже сравнивать мероприятия и многое другое.
Если уж на то пошло, то правильней было бы опубликовать полный перечень программных параметров-факторов с указанием потенциального вклада (веса) каждого в общий успех проекта. Естественно, это делается по каждому социальному результату (outcome). Очень скоро эти сведения будут известны по тем прогнозам, которые будут выполняться. Лучше уже сразу ориентировать разработчиков проектов на сведения/знания, «выловленные» из больших массивов, содержащих ту или иную кодификацию уже выполненных проектов. В некоторой степени это напоминает продукты построения теории изменений, где не просто видны причинно-следственные связи, но ещё и указываются веса факторов, влияющих на конечный результат.
Вообще, если уже помогать разработчикам проектов, то тут напрашивается подход, включающий регулярное пополнение баз данных о выполненных проектах. Все, кто разрабатывает и реализует проект должен будет его кодифицировать (частично самостоятельно, а частично – передав документацию проекта соответствующей команде экспертов) и после завершения проекта сообщить о его результатах (тоже в заранее согласованном формате). Но для такой унификации необходимо вселенское соглашение или нормативно введённые стандарты (например, через отчётность налоговым органам). Пусть бы это был целый национальный или всемирный архив. Тогда доступ к нему очень помог бы разработчикам новых проектов.
«Геном» и программная оценка
Заменяет ли предлагаемый Mission Measurement подход традиционную оценку?
Во-первых, это – прогноз, а не анализ того, что получилось. Хотя авторы и говорят, что теперь не нужно ждать завершения проекта и проводить дорогостоящую и длительную программную оценку, чтобы что-то сказать о проекте. Но как мы узнаем, что же у нас получилось? Всё равно придётся в том или ином виде отвечать на этот вопрос. Вообще, «программный геном» – это метод прогноза результата, но не метод его констатации. Прогнозирование – очень важная сторона маркетинга. В данном случае речь идёт о фандрайзинге. Или в управлении программами (пакетами проектов, на каждый из которых подбирается свой исполнитель). А такая деятельность и называется программной оценкой. Причём проводить её необходимо независимо от того, применялся ли «программный геном».
Во-вторых, свойства прогнозного значения неизвестны. Авторы говорят, «мы хотели, чтобы прогноз успеха варьировался не в диапазоне от 0 до 100 процентов, хоть немного сузить его». Пользователю/клиенту они выдают точное (точечное) значение. Пишут ещё что-то типа «плюс-минус 5%», но чтобы так точно утверждать, следует привести математическую модель. По сути, мы имеем дело со статистическим оцениванием. Тогда нужно предъявить, как распределена эта величина.
В-третьих, много вопросов возникает к составу базы данных проектов, по которой строилась модель и по которой осуществляется прогноз для отдельного проекта. Более 80 тысяч проектов – это впечатляет, но – это «капля в море» по сравнению со всем гигантским количеством проектов, которые человечество выполнило за свою историю и даже за последний год. Является ли эта выборка достаточно представительной? Если это только проекты, выполненные в США, то можно ли по ним прогнозировать успех в России? Проблема тут в том, что в распоряжении авторов, похоже, нет формальной (математической) модели, чтобы сказать, какова ошибка их прогноза для других стран и для проектов, в которых применяются совершенно новые методы и подходы к решению социальных проблем (т.е. для инновационных проектов).
В-четвёртых, цена анализа составляет несколько тысяч долларов (судя по неявным высказываниям авторов на презентациях своего инструмента). Анализ занимает от нескольких недель до нескольких месяцев. При этом они говорят: вот видите, как это удобно и выгодно по сравнению с традиционной программной оценкой. Но эта стоимость и продолжительность – как раз соответствует тем ресурсам, которые обычно отводятся в России на полноценную программную оценку проектов среднего масштаба. Возможно, в США это стоит гораздо больше.
Применение
Анализ конкретного проекта осуществляется командой Mission Measurement. Сервис предназначен тем, кто разрабатывает и планирует выполнять проекты и тем, кто принимает решение о его финансировании (донор). Сколько стоит такая услуга, выяснить не удалось.
Входными данными для формирования прогноза служат все доступные сведения о планируемом проекте.
Эти сведения обрабатываются командой специалистов. Методология не раскрывается. Авторы однозначно устанавливают, что сам клиент не может выполнить эту работу. Но дело тут не в закрытости, а необходимости обеспечить объективность. Требуется квалификация исполнителей, именно для того, чтобы максимально снизить субъективизм. Это уже определяет один из недостатков методологии.
Работа экспертов заключается в кодификации проекта на основе нестрого формализованной документации. Дальше, как можно предположить, с «геномом» работает компьютерная программа. Она выдаёт основные показатели, которые включаются в Карту-прогноз. Но, судя по различным примерам, на этом работа экспертов не завершается. Нужно добавить рекомендации (хотя в будущем это тоже можно будет автоматизировать). Кроме того, в Карту можно включить много другой информации, которую, безусловно, анализируют эксперты. Кто и как решает, что ещё (из того, что известно о планируемом проекте экспертам) сообщить разработчикам проекта, непонятно.
Что дальше?
Наверняка в недалёком будущем, стандартом станет сообщать всю информация и все знания, которые удалось извлечь из опыта (базы данных) завершённых проектов. Клиентов Mission Measurement не устроит выдача одного параметра. Решение задачи кодификации проекта не очень сложно, если зафиксировать ограниченный круг задач, которые решаются. Проблема сейчас заключается в том, чтобы делать это не только для решения одной задачи, но держа в голове весь набор задач, которые можно решать на основе опыта уже выполненных проектов. Развитие технологии «больших данных» приведёт к стандартизации и унификации, развитие алгоритмов искусственного интеллекта и создании баз знаний повлечёт появление множества удобных инструментов для решения задач оценки качества разрабатываемого проекта и прогнозирования его результативности и эффективности.
Подход Mission Measurement охватывает узкий круг задач при том, что применяемая методология подразумевает широкие коллективные усилия. Если основные заинтересованные игроки не поддержат эти усилия, то Mission Measurement придётся самостоятельно заниматься «отлавливанием» и кодификацией чужого опыта. Это очень трудоёмко. И, скорее всего, экономически неоправданно. Удастся ли поставить это на коммерческие рельсы? Можно предположить, что новые технологии и методы, позволяющие решать более широкий круг задач, «накроют» те задачи, которые решает Mission Measurement, сделав этот проект компании неконкурентоспособным. Впрочем, у неё есть возможность, постараться окупить свои вложения в ближайшие 2-3 года, не расширяя базу данных осуществлённых проектов, а «продавая» уже созданный на данный момент инструмент и накопленные данные.
Более того, очень скоро встанет вопрос о применении этой база данных выполненных проектов в процессе разработки проекта. Можно будет в интерактивном режиме, отвечая на вопросы компьютера, «прокрутить» возможные проектные идеи и оценить затраты на их реализацию. Только имея такой расклад, можно приступать к детальной проработке будущего проекта. Разработчикам проектов не нужно будет придумывать ничего нового – сформулировав проблему и цель, можно будет обратиться к базе данных, чтобы взять уже готовые разработки. Причём можно будет выбрать по разным параметрам, включая и стоимость, и эффективность. Думается, что запросы пользователей очень скоро вынудят Mission Measurement начать оказывать эту услугу. Она менее трудоёмка, даёт гарантированный результат, использует уже готовые данные. Остаётся только дополнить инструмент, который не представляет методологических проблем.
Другое дело – инновационные проекты. Сейчас такие проекты появляются, поскольку разработчики каким-то образом генерируют новые подходы к решению проблемы. База данных завершённых проектов, во-первых, позволяет определять (в зависимости от её полноты) является ли некоторый проект инновационным. Кодификация должна позволять отвечать на этот вопрос. Во-вторых, база данных позволяет искать новые идеи, используя базу данных – например, рассматривая какие методы применялись в других сферах, для решения других задач и примеряя мысленно их к совершенно новой сфере. База данных – хороший ресурс для поиска новых идей. В-третьих, если потребность в инновационных проектах возникает тогда, когда сообщество по каким-то причинам не устраивают старые схемы (нужно сокращать финансирование и нужно искать способы решения тех задач, но с меньшими затратами). База данных завершённых проектов даёт ориентиры стоимости, эффективности, продолжительности и т.д. С её информацией можно обосновывать необходимость применения инноваций. Основная проблема инновационного проекта – непредсказуемость результата. Продвигая инновацию, убеждая донора в финансировании более рискованного проекта, на первый план будет выходить вопрос: при каком проценте успеха инновационный проект будет экономически (или по какому-то другому параметру) более выгоден, чем проект, выполняемый по уже известной схеме, проверенными методами, «по старинке». С помощью базы данных завершённых проектов можно будет устанавливать целевое значение успешности (в терминах «геномного подхода» – Efficacy Rate – действенности, отдачи). Тогда разработку проекта и его мониторинг (как инновационного) можно будет планировать, сосредоточившись на целевом значении этой «отдачи».
Разработчикам нужно будет уметь обосновывать, при каком уровне успеха инновационный проект будет экономически более выгоден, чем проект, реализуемый «по старинке», уже проверенными методами.
«Программный геном» и первый опыт его применения привносит много вопросов и идей дальнейшего развития «взаимоотношений» доноров и исполнителей проектов.
Самый главный урок: общество должно готовиться к унификации и стандартизации, а также к информационной открытости. Это даёт небольшой выигрыш исполнителям проектов, вносит ограничения для разработчиков. Сильно повышает конкуренцию в борьбе за ограниченные ресурсы. Но выгоден донорам, поскольку позволяет снизить издержки на оценку качества предлагаемых для финансирования проектов, уменьшить риски, оптимизировать пакетное (портфельное) финансирование, когда нужно выбрать несколько проектов при общем ограничении грантового фонда. Это стимулирует инновации в социальной сфере и даёт сильный выигрыш для всего сообщества.
К этому нужно готовиться уже сейчас. Как минимум это включает:
- разработку и нелёгкую борьбу за публичное нормативное признание (закрепление) стандартов в описании проектов (и социальной сферы);
- разработку и компьютерную реализацию алгоритмов обработки этих стандартизованных описаний;
- формирование механизмов аккумуляции информации о проектах и результатах их выполнения (формирование базы знаний). Тут недостаточно придумать хороший механизм, нужно позаботиться о том, чтобы его использование было выгодно пользователям. Нужно учесть, что речь идёт не только об описании проекта в стандартизованной форме и представлении его для включения в базу данных, но и о том, чтобы после завершения вернуться к этому же проекту, чтобы кодифицировать непосредственные результаты (outputs и outcomes), а потом и второй раз – долгосрочные результаты (impact), и тоже донести всю эту информацию до базы данных;
- разработку и отладку открытых механизмов пользования формируемыми базами данных.
Раз уж такая задача встала, то целесообразно начать с аналитических и интеллектуальных шагов, цель которых спрогнозировать, как будут меняться потребности разных заинтересованных сторон вследствие развития информационных технологий.
Источники:
- Saul J. Cracking the Code on Social Impact. 6 февраля 2014 – http://www.ssireview.org/blog/entry/cracking_the_code_on_social_impact
- Saul J., Groch M. Introducing the Impact Genome Project. 9 апреля 2014 – http://www.ssireview.org/blog/entry/introducing_the_impact_genome_project
- Impact Genome Project – http://missionmeasurement.com/work/impact-genome
- Saul J. Introducing the Social Value Scorecard™ and the Social Value Index™. 4 июня 2014 – http://missionmeasurement.com/uploads/documents/Introducing_the_Social_Value_Scorecard_and_Social_Value_Index.pdf
- Saul J. Disrupting Evaluation: Using Universal Outcomes to Measure Impact. 18 марта 2014 – http://missionmeasurement.com/uploads/documents/Disrupting_Evaluation—_Using_Universal_Outcomes_to_Measure_Impact.pdf
- Saul J. Impact Genome Project™ Keynote at Do Good Data. 16 мая 2014 – http://missionmeasurement.com/ideas/video_entry/the-impact-genome-project
- Saul J., Gasser N. Cracking The Code On Social Impact at Skoll World Forum 2014, 26 апреля 2014 – http://missionmeasurement.com/ideas/video_entry/skoll-world-forum-cracking-the-code-on-social-impact
- Saul J., Gasser N. Using Big Data to Predict Social Impact – https://event.webcasts.com/starthere.jsp?ei=1043480
СКАЧАТЬ СТАТЬЮ В ФОРМАТЕ PDF